Fundamentals and High Level Overview
System Design Process
- Gather requirments
- Back of envelope calculations
- API design
- Architectual design
1 Database
- sequential reads and writes are always cheaper than random reads and writes
- want to keep data that is frequently read together close together
- want to keep data that is frequently written to together close together
- indexes can be used to speed up reads, but often at the expense of slowing down writes
- without index, we can just write data sequentially, that is basically a WAL (Write Ahead Log), but reads will be slow: O(n)
1.1 Hash Index
- reads and writes are O(1)
- usually in memory
- range query is impossible, because each data is written into random memory/disk addresses, they're not sequential, so range query is essentailly N reads, where N is the size of the range
1.2 B+ Tree Index
- tree structure allows for O(log n) read speed
- data are written together on disk (for primary keys), so range query is fast
- for indexes other than primary keys, range query is also fast because the pointers to the range data are stored together (the leaves of the B+ tree)
- but data on disk are stored sequentially according to the primary key, not second indexes
- which means even though pointers are used for fast query reads, but the actual data are scattered around the disk, so querying is still not as efficient as primary key index
1.3 LSM Tree Index (Memtable + SSTables)
-
writes are fast because they're written to the memtable in memory first
-
memtable itself is also a tree - self balanced binary tree
-
data in memtable is being flushed to disk periodically as SSTables
-
SSTables are compacted into a new SSTable for the next layer to reduce the size because only the latest update for a key is relevant and stored
-
read is slow, because it requires a linear scan (O(n)) of all the memtable and SSTables until the key is found
- if a key is really really old, at worst case scenario, all SSTables would need to be scaned to find that key
1.4 Transactions
- ACID
- Atomicity: all or nothing write
- Consistency: write does not break rules
- Isolation: concurrent transactions don't intefere with one another
- Durability: data are recoverable during system failure
- Isolation Levels
- Dirty Read: reading uncommited data from another transcation
- Non Repeatable Read: in a transaction, reading twice result in different data from the same row (because the row was updated by some other process)
- Phantom Read: in a transaction, running the range query twice result in different sets of data
- https://www.youtube.com/watch?v=GAe5oB742dw


1.4.1 Serializable
-
it appears to the writer as if all transactions ran on a single thread, no need to worry about race conditions
-
There are several ways of ensuring serializability in a database:
- actually running on a single thread
- pessimistic concurrency control: suitable for high probability of concurrent write, because locking is better than read-write-write overhead
- optimistic concurrency control: suitable for low probability of concurrent write
Pessimistic Concurrency Control
- hold locks on all read-from and written-to database rows, others must wait
- For example, MySQL supports Pessimistic
-
# acquires an exclusive lock on the selected rows select ... for update # locks entire tables for exclusive access by the current transaction lock tables ... write:
-
Optimistic Concurrency Control
- allow concurrent updates, but any update needs to compare data before and after, if they dont match, that means another process has updated the data, so abort. but abort is expensive.
- For example, MySQL supports Pessimistic, but optimistic concurrency control con be achieved with a "version" column in table:
-
select id, version from table where id = <id> Update table where id = <id> and version = <stored_version> # if affected rows == 0, resolve the conflict
-
1.4.2 Who supports transactions?
- Most SQL DB do
- NoSQL generally don't support transactions because transactions are expensive
1.5 Row vs Column Store
- it all depends how application consumes data
- if data in the row are always needed together, like a user profile, then row store makes sense
- but if data in the column are always needed together, like in a time series analysis, then column store makes sense
1.6 Replication
-
database failures are common
-
replication logs are used to keep rep DB synced
-
Synchronous Replication
- all replicas needs to be updated before success confirmation
- strong consistency
- but it is slow, uses a lot of network bandwidth
- and if a single replica is down, we cannot commit!
-
Asynchronous Replication
- eventual consistency
- only a subset of replicas must confirm success
- but some replica can contain stale data
- and write conflicts may occur (if not using single leader replication)
- even though, it is still preferable than synchronous replication
-
Single Leader Replication
- write to one, replicate to many
- simple to implement
- write throughput is limited
- if leader fails, a new one needs to be picked, and the new one may not be up to date
- during failover, we cannot complete any writes
-
Multi Leader Replication
- increased throughput, but need to resolve write conflicts
- Last Write Wins to resolve write conflicts
- but timestamps are unreliable
- Storing Siblings (vector clock) to store write conflicts
- let user decide which value to use in case of write conflict
- some databases support write conflict resolutions
-
examples?
-
-
Leaderless Replication
- write and read to many nodes at once
- no leader, so no failover
- but are bottlenecked by the slowest write/read nodes
- if W + R > N, we have a quorum
1.7 Sharding
- we need to pick a "good" shard key, so that application only interact with as less shards as possible (ideally just one)
1.7.1 Key Range Sharding
- good for range queries, but bad for "hot spot", for example, names starting with letters A-D is far more than names starting with letters X-Z
1.7.2 Key Hash Range Sharding
- a hash ideally distribute data more evenly
- but now we loss the convenience of range queries
- consistent hashing can be used to help the issue where shards are added or deleted
- but consistent hashing also has its drawbacks, to make the data more evenly distributed, consistent hashing basically divides the hashing ring into very small segments, and assign the segments to nodes. but to achieve an ideal level of evenly distribution, the number of segments would need to be very big, and maintaining this segment to node mapping takes a long of memory.
- to mitigate this issue, something called "Jump Hashing" can be used
1.7.3 Secondary Indexes
- local secondary index is helpful, but it needs to be designed to work in a single shard only
- if the data in the indexed field are scattered across multiple shards in random, then a secondary index would need to be global
- but global secondary index is expensive, it requires cross shard data comparison
- MySQL and PostgreSQL doesn't support GSI (global secondary index)
- DynamoDB supports GSI, cassandra has a similar feature called "Materialized Views"
1.7.4 Two Phase Commit
- a mechanism to make sure a write going to more than one node can be done in a synchronous way
- coordinator: node1, node2, prepare to insert data
- node1: ok, locked
- node2: ok, locked
- coordinator: now commit
- node1: succeeded
- node2: succeeded
1.7.5 Asynchronous Global Secondary Index
- to avoid two phase commit, we can use eventual consistency (asynchronous GSI)
- Change data capture (CDC)
1.7.6 SQL vs. NoSQL in Sharding
- There is no direct comparison between SQL and NoSQL, NoSQL just drops alof of features so it can be scallable, they have their unique use cases
2 Batch Processing
- run large distributed computations over huge datasets
- distributed computing is challenging:
- hardware failures
- balancing load across nodes
- avoiding any concurrency bugs
- Batch processing frameworks abstract away many of these difficulties from us
3 Stream Processing
- Producer genreate data, broker store data, consumer process data
- asynchronous processing of application events
- joining multiple data streams together
- time-based grouping of data
3.1 In Memory Message Broker
- a queue in memory, removes messages as consumers consume them
- many message patterns, including round robin
- high throughput with multiple consumers, but messages may not be processed sequentially because it doesn't wait for confirmation from the first consumer before sending the next message to the next consumer, or even to the same consumer. For example, first message failed, second message succeeds
- RabbitMQ
3.2 Log Based Message Broker
- data are stored on disk, not deleted, and data can be "replayed"
- broker keeps track of each consumer's last read offset
- within a partition, every consumer handles every single message
- Kafka
3.3 Stateful Consumer Frameworks
4 Other types of Storage
4.1 Search Index
- "full text search"
- a mapping between token (word) to a list of document Ids
4.2 Distributed File System
4.3 Graph Database
- None Native Graph DB: represent edges between two graph nodes (many to many relationship)
- Native Graph DB
- pointers on disk, so traversing an edge is O(1)
- but random reads on disk is still not performant
4.4 Object Store
- Amazon S3
4.5 Time Series Database
- uses columnar store
- efficient storage and retrieval for time series data
4.6 GeoSpatial Indexes
- convert lat and lng into 1 dimensional key
- Geohash
4.7 Coordination Services
- partitions on each shard? who is the leader? who is holding the lock?
- Consensus algorithms
4.8 Caching
- disk is slow, use memory
- Write through cache
- two phase commit, write to cache and DB at the same time
- Write around cache
- data is written to DB, data is pulled into the cache on a miss
- fast writes
- but potentially stale data in the cache, expensive cache miss on first data read
- Write back cache
- data is written to cache and read from cache
- data is asynchronous synced to DB
- but if cache fails, data is lost
4.9 CDN
- geographically distributed caches
5 Load Balancing
- Round robin
- Consistent Hashing (based on network data or application level data)
- Load balancer also need to be replicated
- Active-Active configuration
- Active-Passive configuration
6 System Design Patterns
- there are many common themes
6.1 Contending Updates
- many writes to the same key, such that they conflict with one another
- examples: distributed counter, order inventory on popular products
- solutions;
- writes to the same DB, use locking (too slow)
- multiple DB leaders, eventual consistency
- stream processing (events go to a log based message broker, and processed in small batches)
6.2 Derived Data
- need to keep 2 DB in sync
- examples: global secondary index, data transformation on slow DB
- solutions:
- 2 phase commit
- change data capture (record changes and saves to a message broker, then consume in batches)
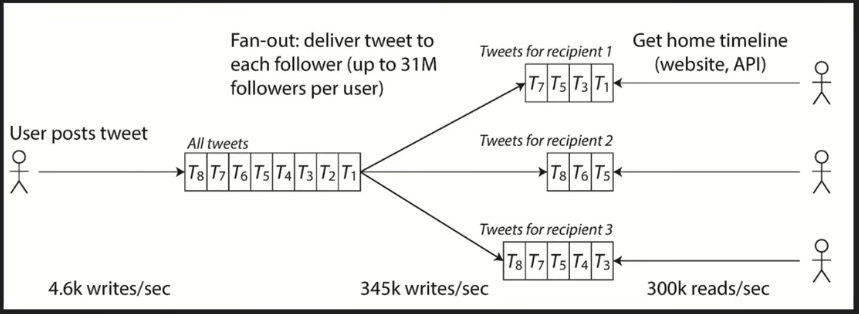
6.3 Fan Out
- Deliver data at write time directly to multiple interested parties to avoid expensive read queries or many active connections on receiving devices
- examples: push notifications, news feed, mutual friend lists, stock price delivery
- solutions:
- synchronous delivery to every interested parties (naive, slow)
- asynchronous delivery via stream processing
- sink message to log based message broker, in consumer logic figure out all parties that are interested, and send to them accordingly
- Flink
-
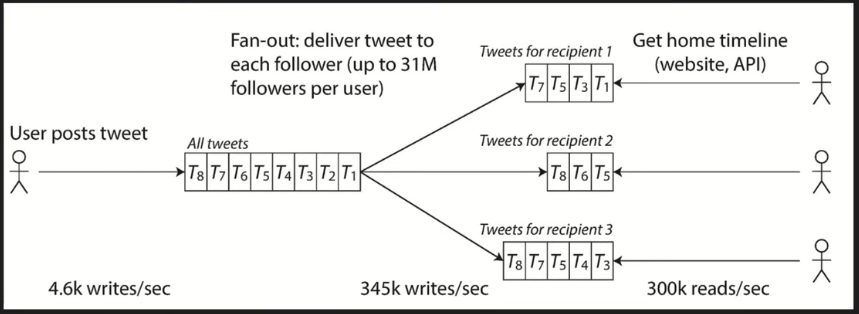
- but what about "popular message" where fan out have millions of receiver?
- hybrid approach: majority of messages are delivered directly to destination caches
- popular messages go to the "popular message cache"
- client side query from both caches
6.4 Proximity Search
- find close items
- examples: uber driver search, door dash, yelp, etc
- solutions:
- build indexes on lat and lg (too slow)
- use a geospatial index
- data needs to be partitioned, use bounding boxes are partition methodology
- certain geopgraphic areas are much more popular than others
6.5 Job Scheduling
- run a series of tasks on one worker in a cluster
- example: build a job scheduler, Netflix/Youtube video upload encoding
- solutions:
- round robin jobs into log based message broker partition (naive)
- one consumer per parition, slow jobs delay other jobs
- In memory message broker delivery messages round robin to workers
- slow jobs do not prevent jobs behind them
- round robin jobs into log based message broker partition (naive)
6.6 Aggregation
- distributed messages that need to be aggregated by some key or time
- example: metrics/logs, job scheduler completion messages, data enrichment
- solutions:
- write everything to a distributed DB, run batch job (slow results)
- stream processing, all messages go into a log based message broker, partition based on their aggregation key
- stream processing consumer frameworks handle fault tolerance for us
6.7 Idempotence
- run jobs twice should have the same effect of run it once
- examples: one time execution in job scheduler
- solutions:
- 2 phase commit (slow)
- idempotency keys
- use a unique key to identify the event
6.8 Durable Data
- you have data that absolutely cannot be lost once written
- example: financial transactions
- solutions:
- sync replication (navie, if any replica fails, it blocks the workflow)
- distributed consensus
- can tolerate node failures and still proceed
- fairly slow for reads and writes, so using change data capture to derive read optimized data views can be very beneficial here
Bloom Filter
- in situations where read is not efficient (like a LSM tree), use bloom filter can eliminate some of the non-existing keys, thus return "no, key is not there" to save read time.
- it may produce falst positives (it says it's there but it is actually not there) because of hash collisions
- How to choose an appropriate size for bloom filter?
- for a chosen expected number of keys and acceptable false positive rates, use this formula:
-
m = -n * log2(p) / (log(2))^2 - n = number of keys
- p = acceptable false positive rates
- m = size of bloom filter in bits
-
- optimal number of hash functions (k):
-
k = (m / n) * log(2)
-
- for a chosen expected number of keys and acceptable false positive rates, use this formula:
C10K problem?
- the challenge of designing and implementing a server that can efficiently handle a large number of concurrent client connections, specifically 10,000.
- solution:
- asynchronous I/O
- Non-Blocking I/O
- Efficient Data Structures
- Connection Pooling
Change Data Capture
- captures changes made within a database
- Implmentations:
- Query based
- Trigger based
- Log based
- Proprietary (developed by database vendor) based
Idempotent
- some operation is idempotent if it always returns the same result.
- Ex, x=5 is idempotent while x++ is not
Thundering Herd problem?
- when a large number of requests try to access a resources in a small time frame due to reasons like cache eviction, hardware restart, etc.
- Flooded backend may further cause system failures
- To mitigate this issue
- randomized cache expiration time
- rate limiting
- backend sharding
- asynchronous cache updates
- backoff time on client side
Gossip Protocol
- a protocol to detect node failures in a distributed and de-centralized cluster
- each node passes information (heartbeat, timestamp, etc) to a random set of other nodes to let them know its still alive
- other nodes, upon receiving the information, adds information about it self, and pass those information to another set of random nodes
- eventually all nodes will be ping and get the updated information.
- If after a while, all of the nodes haven't heard about one particular node, than that node is considered as down.
- Cassandar uses Gossip Protocol to detect node failures.
123